[ Program Manual | User's Guide | Data Files | Databases ]
Overlap compares two sets of DNA sequences to each other in both orientations using a WordSearch style comparison.
Overlap accepts two sets of sequences as input and uses the algorithm of Wilbur and Lipman (Proc. Natl. Acad. Sci. USA 80; 726-730 (1983)) to compare each sequence of the first set with each sequence of the second set, in both orientations. Thus, Overlap runs a WordSearch reiteratively, using the first set of sequences as queries. Unlike WordSearch, Overlap looks for overlaps between sequences rather than simply regions of similarity. An overlap is a highly similar region between two sequences that runs the entire length of a register of comparison. Overlap lists the position, length, and stringency of discovered overlaps in an output file.
Here is a session using Overlap:
% overlap OVERLAP what query sequences ? mu*.seq To what other sequences (* mu*.seq *) ? What word size (* 5 *) ? What fraction of the words in an overlap must match (* 0.80 *) ? Integrate how many adjacent diagonals (* 3 *) ? What is the minimum overlap length (* 10 *) ? What should I call the output file (* overlap.dat *) ? Reading ............ Comparing ............ %
Here is the output file:
OVERLAP of: mu*.seq
to: mu*.seq
Min overlap fraction: 0.80 Min overlap length: 10 Integral width: 3
September 24, 1998 17:00
Sequence1 Strand Pos Sequence2 Strand Pos Length Matches Ratio Len1 Len2 ..
mu10.seq + 2 mu5.seq - 1 230 205 0.89 361 230
mu6.seq + 183 mu5.seq + 1 114 109 0.96 296 230
mu2.seq + 2 mu23.seq + 1 256 254 0.99 328 256
mu27.seq + 23 mu18b.seq - 1 203 199 0.98 290 203
mu27.seq + 260 mu26b.seq + 1 31 34 1.10 290 173
mu27.seq + 222 mu26.Seq + 1 44 44 1.00 290 44
mu27.Seq + 224 mu18.Seq - 1 42 42 1.00 290 42
mu27.Seq + 226 mu32.Seq - 1 40 40 1.00 290 40
mu27.Seq + 222 mu9.Seq + 1 39 39 1.00 290 39
mu26b.Seq + 163 mu27.Seq + 1 11 29 2.64 173 290
mu26.Seq + 3 mu18.Seq - 1 42 42 1.00 44 42
mu26.Seq + 5 mu32.Seq - 1 40 40 1.00 44 40
mu26.Seq + 1 mu9.Seq + 1 39 39 1.00 44 39
mu18.Seq + 1 mu32.Seq + 1 40 40 1.00 42 40
mu18.Seq + 6 mu9.Seq - 1 37 37 1.00 42 39
mu32.Seq + 6 mu9.Seq - 1 35 35 1.00 40 39
In this example, the overlap pairs are divided into three groups, or overlap clusters, separated by blank lines. Each cluster consists of overlapping fragments that could be chained together into a single, continuous assembly.
The output file lists the length, position, and percent similarity (ratio) of each overlap in descending order of sequence and overlap length. It also gives the orientation of each sequence.
Overlap accepts two separate groups of multiple (one or more) nucleotide sequences as input. You can specify multiple sequences in a number of ways: by using a list file, for example @project.list; by using an MSF or RSF file, for example project.msf{*}; or by using a sequence specification with an asterisk (*) wildcard, for example GenEMBL:*. If Overlap rejects your nucleotide sequence, see Appendix VI for information on how to change or set the type of a sequence.
WordSearch uses the same comparison algorithm as Overlap. WordSearch, however, accepts a single query sequence as input and finds regions of similarity rather than overlaps. LineUp is a screen editor for editing and displaying overlapping sequences.
The total length of bases in any sequence set may not exceed 350,000. The word size must be between 1 and 30. The minimum overlap length must be between 1 and 1,000. The program cannot store more than 10,000 overlaps. If this number is exceeded, the program stops after suggesting that you increase the stringency to reduce the number of overlaps.
Overlap, like WordSearch, identifies sequence similarities using a Wilbur and Lipman-style word comparison (see the WordSearch entry in the Program Manual for information regarding the details of this algorithm and considerations about using this search). Overlap differs from WordSearch in that it accepts a set of query sequences as input and reports overlaps rather than regions of similarity.
Overlap removes gap characters (. and ~) from the input sequences before comparing them.
For considerations in using a word comparison, see the CONSIDERATIONS topic in the WordSearch entry of the Program Manual.
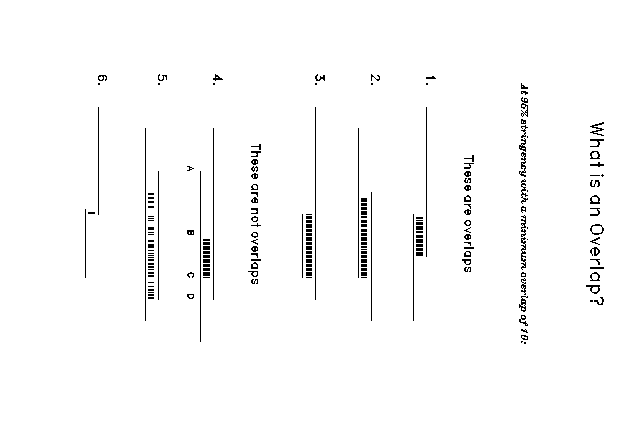
Overlap recognizes certain regions of similarity to be overlaps based upon the strength of similarity across the entire register of comparison and the length of the register itself. These requirements correspond to the stringency and minimum overlap values that are set in response to Overlap's prompts. A stringency of .95 means that 95% percent of the bases in a given register of comparison must match for that similarity to be recognized as an overlap. A minimum overlap of 10 means that a given register of comparison must contain at least 10 bases to qualify as an overlap. The figure at the end of this entry illustrates these requirements. Examples four through six of this figure are not overlaps for the following reasons:
5. -- These sequences are not similar enough to contain an overlap. The minimum stringency requirement for overlaps is not met.
6. -- The register of comparison containing the similarity is not long enough; overlaps must be larger than the minimum overlap length.
To make the search for overlaps more tolerant of gaps between sequences, Overlap combines the scores of a user-defined number of adjacent diagonals, or registers of comparison (see the ALGORITHM topic in the WordSearch entry of the Program Manual). Thus, the reported percent similarity or ratio may be larger than the actual ratio and may even be greater than 100%. Combining the scores of adjacent diagonals in Overlap may cause the listed overlap position to be a few bases removed from the actual overlap position.
If you are looking only for weak overlaps, you can use -UPPERlimit to specify a maximum stringency. Overlaps containing more than this maximum fraction of matching bases are not reported in the output file. For example, if you run % overlap -STRIngency=0.6 -UPPERlimit=0.7, your output only contains overlaps in which 60 to 70 percent of the bases matched.
All parameters for this program may be added to the command line. Use -CHEck to view the summary below and to specify parameters before the program executes. In the summary below, the capitalized letters in the parameter names are the letters that you must type in order to use the parameter. Square brackets ([ and ]) enclose parameter values that are optional. For more information, see "Using Program Parameters" in Chapter 3, Using Programs in the User's Guide.
Minimal Syntax: % overlap [-INfile1=]mu*.seq -Default Prompted Parameters: [-INfile2=]mu*.seq specifies second search set -WORdsize=5 sets the length of word for a match -STRIngency=.80 sets the minimum fraction of required word matches -MINOverlap=10 sets the minimum overlap length -INTegrate=3 sets the number of diagonals to integrate [-OUTfile=]overlap.dat names the output file Local Data Files: None Optional Parameters: -UPPERlimit=.90 sets the upper limit on stringency
None.
You can set the parameters listed below from the command line. For more information, see "Using Program Parameters" in Chapter 3, Using Programs in the User's Guide.
sets the word size for comparison between sequences. The range of word sizes is from 1 to 10.
sets the minimum fraction of bases that must match for a given register of comparison to qualify as an overlap.
sets the minimum number of bases that must be present for a given register of comparison to qualify as an overlap. The minimum overlap length must be between 1 and 1,000.
sets the number of adjacent diagonals used to calculate scores.
sets an upper limit on the stringencies on which Overlap reports. This creates a stringency range between the upper limit and the minimum stringency within which overlaps must fall.
[ Program Manual | User's Guide | Data Files | Databases ]
Documentation Comments: doc-comments@gcg.com
Technical Support: help@gcg.com
Copyright (c) 1982, 1983, 1985, 1986, 1987, 1989, 1991, 1994, 1995, 1996, 1997, 1998 Genetics Computer Group Inc., a wholly owned subsidiary of Oxford Molecular Group, Inc. All rights reserved.
Licenses and Trademarks Wisconsin Package is a trademark of Genetics Computer Group, Inc. GCG and the GCG logo are registered trademarks of Genetics Computer Group, Inc.
All other product names mentioned in this documentation may be trademarks, and if so, are trademarks or registered trademarks of their respective holders and are used in this documentation for identification purposes only.
