{kind=link}

[ Program Manual | User's Guide | Data Files | Databases ]
Overview
What are Data Files?
Default vs. Local Data Files
Using Local Data Files
Creating or Modifying Data Files
Using a Special Kind of Data File: A Scoring Matrix
Using Scoring Matrices
Converting Scoring Matrices to a Different Format
Converting Pre-Version 9 Scoring Matrices to the New Format
Converting BLAST-Format Scoring Matrices to GCG Format
This chapter explains how Wisconsin Package programs work with data files. Data files contain nonsequence information which some programs need to perform their analyses.
You are not required to create or specify data files to successfully use Wisconsin Package programs. All programs that require a data file have a default file they use, so as a new user you needn't worry about the information in this chapter.
This chapter is for intermediate to advanced users who understand how programs access data files and who want to modify them or create their own files to customize their analyses. You'll learn how to
By now you've learned the basics of how to use Wisconsin Package programs to analyze the nucleic acid or protein sequences that are stored in the sequence databases or in your own personal sequence files. Additionally, many programs require nonsequence information, or data files, which they use to analyze the sequences. For example, one of the nucleic acid mapping programs, Map, requires two data files: enzyme.dat, which contains restriction enzyme names and their corresponding recognition sites; and translate.txt, which associates codons with their corresponding amino acids.
All programs that require a data file have a default file they use, so as a new user, you need not worry about supplying one. These default files are public--that is, they are available to everyone who uses the Package. Default data files are located in the public directory with the logical name genrundata. When you run a program that requires a data file, it automatically finds the appropriate default file in this directory; this means you don't have to specify the directory and filename.
GCG also provides alternative data files you can use with a program instead of the default file. There may be times when you want to use an alternative data file rather than the default one. For example, if you're using the CodonPreference program to analyze a Drosophila sequence, you may want to use the alternative codon frequency table drosophila_high.cod rather than the default table, eco_high.cod, which is more appropriate for bacterial sequences. These alternative data files are located in the directory with the logical name genmoredata.
You also can create your own data files, or you can copy a default or alternative public data file to your local directory and modify it to suit your needs. These files are known as local data files. For instance, let's say you're working with the Map program and you create a data file of enzymes specific to your research. This personal data file, then, would be available only to you. When you have a local data file a program can use, the program tells you so with a message similar to *** I read your "data" file *** to remind you that you have a data file in your directory that the program is using instead of the default file.
You can find what default data file a program uses in a number of places:
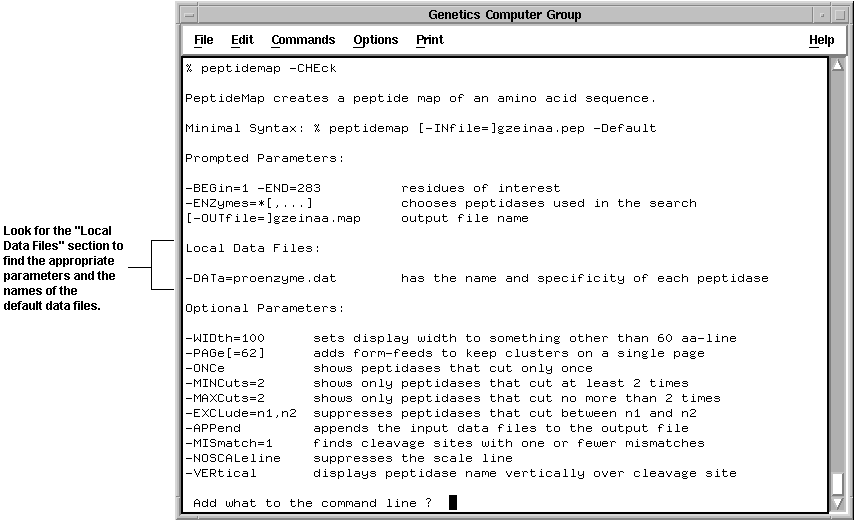
Program Manual. Check the "Local Data Files" topic toward the end of each program entry in the Program Manual. This topic provides you with a summary of how data files work and briefly describes each default data file used by the program. The "Command Line Summary" topic of each program in the Program Manual also lists any default data files the program uses.
In addition, you can find default and alternative data files listed and described in Appendix VII of the Program Manual.
Command-Line Summary. Turn to the individual program summaries in the "Programs A-Z" section of the Command-Line Summary and check the "Local Data File" subtopic within each program.
Online documentation. Display the default data file(s) a program uses by running the program with the -CHEck parameter. The program displays the command-line parameters, including the default data files and parameters you would use to specify alternate data files.
Data file information is also available online in GenHelp and GenManual. You can find default data files listed in each program within the subtopic "Local Data Files."
Local versions of data files are always optional; you are never required to supply one because there is always a default. However, if you choose to provide a local data file or an alternative public data file, you can do so in a number of ways. Wisconsin Package programs have a hierarchy of locations they check for data files.
Most programs check for data files in the order described below. (Scoring matrices use a different search order, described in more detail in "Using a Special Kind of Data File: A Scoring Matrix" later in this chapter.)
The MyData directory is a special feature within the Package. Because programs automatically search for the logical name MyData, you need not worry about what directory you are in when you run a program that uses a data file (as you would in number 2 above). The program automatically finds the MyData directory. For more information about defining logical names for directories, see "Defining and Using Logical Names for Directories" in the "Working with Directories" section of Chapter 1, Getting Started.
If you frequently use alternative data files or have modified or created your own data files, it is a good idea to set up a directory with the logical name MyData and place all of your local data files in that directory.
There are many different types of data files you can use to customize a program's analysis. For more information about these data files, see Appendix VII of the Program Manual.
Restriction Enzymes (REBASE). The Wisconsin Package mapping programs Map, MapSort, and MapPlot read restriction enzyme names, recognition sites, cut positions, and overhangs from a restriction enzyme data file.
Proteolytic Enzymes and Reagents. The Wisconsin Package peptide mapping programs PeptideMap and PeptideSort require a data file that lists peptidases and proteolytic reagents and the residues at which they cleave.
Transcription Factor Recognition Sites. FindPatterns, Map, MapSort, and MapPlot can optionally use this data file, which lists the recognition sequences for eukaryotic sequence-specific transcription factors.
Scoring matrices follow slightly different rules than other data files. For more information, see "Using a Special Kind of Data File: A Scoring Matrix" later in this chapter.
Data files are local when they are located in your directory. Local data files may be files you created, or they may be public data files you copied to your local directory to modify and use. When you have a local data file a program can use, the program tells you so with the message
*** I read your "data" file. ***
This message reminds you that you have a data file that the program is using instead of the default.
Choose from the following.
You also can find the parameter(s) listed in the "Local Data Files" section of each program in the Program Manual and Command-Line Summary. In addition, this information is available in the online documentation GenHelp and GenManual.
If the file is in a directory other than your current directory, specify the directory path: -DATa=/directory/filename, for example -DATa=/project/my_enzyme.dat. If the file is in a directory with a logical name, specify the logical name followed by a colon and the filename: -DATa=logical_name:filename, for example -DATa=proj:my_enzyme.dat.
You can find the default data filename by adding -CHEck on the command line when you run the program. You also can find this information listed in the "Local Data Files" topic of each program in the Program Manual and in the online documentation GenHelp and GenManual.
Note: To save your logical names from one session to the next, add the logical name definitions to your .gcgrc (csh) or .gcgrc.ksh (ksh) file. For more information, see "Defining Logical Names" in the "For Advanced Users" section of Chapter 1, Getting Started.
Note: Although you defined MyData as the logical name for datadir, UNIX shell commands do not recognize logical names. Therefore, to use logical names with UNIX commands, you must use the Wisconsin Package program Name to expand the definition of MyData and enclose it all in backquotes (`) (for example `name -f MyData`) or copy the file to the specific directory (datadir).
When you run a program, it automatically checks if you have a MyData directory and uses the data file with the same name as the default data filename.
Note: When you place a data file in MyData and rename it to the default data filename, all programs that require a data file with that name automatically use it each time you run the program. Make sure this is what you intend before placing files in MyData.
TIP - GCG provides default and alternative data files for you to use. Because data files require a special format, you may find it easier to modify one of these files rather than create a local data file from scratch. You can find the default data files in the directory with the logical name genrundata and alternative data files in the directory with the logical name genmoredata. For more information, see "Creating or Modifying Data Files" in this chapter.
GCG provides default and alternative data files for you to use. However, there may be times when you want to create a new data file or modify an existing one to customize it to your needs. For instance, you may want to create your own customized enzyme data file containing only the restriction enzymes specific to your mapping project. Because data files have a particular format they must follow, we suggest that if you want to create a new data file, you should use an existing data file as a template. You can do this by using the Fetch program to copy the data file to your directory and then modifying it with a text editor. Once you copy the file to your directory, it becomes a local data file.
Note: All data files require a specific format. Most data files, such as translation tables, scoring matrices, codon frequency tables, protein analysis files, and energy tables, require two periods (..) between the documentary heading and the table itself. In addition, all data files supplied by GCG have a file type, for example !!CODON_ FREQUENCY 1.0, that appears on the first line of the file. Do not edit or delete this line. For more information about data file formats, see Appendix VII of the Program Manual.
To use the modified data file with a program, see "Using Local Data Files" in this chapter.
A scoring matrix is a table of pairwise relationships between nucleotide symbols or between amino acid symbols. These tables are used by several programs, including database searching and multiple sequence alignment programs. In many ways scoring matrices are like other types of data files used by the Wisconsin Package. However, there are some differences covered in this section that you will want to note.
The Wisconsin Package works with two types of scoring matrices: native GCG matrices and native BLAST matrices. You can find native GCG scoring matrices in the directories with the logical names GenRunData and GenMoreData. If you want to use a native BLAST-formatted scoring matrix, you can use it directly with a Wisconsin Package program without first converting it to GCG format. However, there are reasons you may want to convert native BLAST matrices to GCG format:
Using a scoring matrix is similar to how you use other data files with Wisconsin Package programs. Each program that uses a scoring matrix has a file it uses by default, so you are never required to supply one. However, using scoring matrices differs from using other data files in two ways. 1) You use a different parameter, -MATrix=filename, to specify an alternate scoring matrix on the command line. And 2) if you choose to provide an alternate scoring matrix on the command line, the Wisconsin Package uses a slightly different search order for finding the file you specify. If you specify the directory where the scoring matrix resides, the Package looks only in that directory. For example, -MATrix=./project/pam250.cmp looks only in the /project subdirectory for the file pam250.cmp. However, if you specify the filename alone, for example -MATrix=pam250.cmp, the Package looks for that file in the directories described below. (In contrast, -DATa=filename looks for the file only in your current directory or in the directory you specify.)
The MyData directory is a special feature within the Package. Because programs automatically search for the logical name MyData, you need not worry about what directory you are in when you specify the local data file (as you would in number 1 above). The program automatically finds the MyData directory. For more information about defining logical names for directories, see "Defining and Using Logical Names for Directories" in the "Working with Directories" section of Chapter 1, Getting Started.
If you frequently use alternate data files or have modified or created your own data files, it is a good idea to set up a directory with the logical name MyData and place all of your local data files in that directory.
Use the parameter -MATrix=filename, where filename is the name of a scoring matrix residing in 1) your current directory, 2) the directory with the logical name MyData, 3) the public directory with the logical name genmoredata, or 4) the default public directory with the logical name genrundata.
There are a couple of reasons why you might want or need to convert scoring matrices:
If you have any pre-Version 9 scoring matrices in your personal directories, including the MyData directory, you must convert them to the new format implemented in Version 9.0. When you do so, you will need to specify the scoring matrix as either nucleotide or protein.
Wisconsin Package programs will not accept pre-Version 9 scoring matrices, and they will display the following error message if you try to use one:
*** ERROR, READSCOREMAT cannot read the scoring matrix in the file "filename"!
If this is a scoring matrix created before GCG version 9,
try converting it with "% reformat -OLDCMPformat -PROtein" or
"% reformat -OLDCMPformat -NUCleotide"
All GCG-provided scoring matrices in genrundata and genmoredata are already converted to the new format.
Type % reformat -OLDCMPformat -NUCleotide scoring_matrix or % reformat -OLDCMPformat -PROtein scoring_matrix.
The Wisconsin Package programs work with native BLAST-formatted scoring matrices. Although converting BLAST-formatted scoring matrices to GCG format is unnecessary, you may find it useful to do so. One advantage GCG-formatted scoring matrices offer is that they allow you to set specific gap creation and extension penalties within the scoring matrix file. (If gap creation and extension penalties are not specified within a scoring matrix file, programs determine default values on the fly.) In addition, the Wisconsin Package by default assumes all native BLAST scoring matrices are protein. Because gap creation and extension penalties are calculated differently depending on if the matrix is nucleotide or protein, you may want to convert the BLAST matrices to ensure they are the correct type.
Type % reformat -COMParison scoring_matrix -NUCleotide or % reformat -COMParison scoring_matrix -PROtein.
TIP - Sometimes scoring matrices may be hard to edit because the lines wrap on your screen. To make your task easier, reformat the data file into columns using the command % reformat -COMParison -EQUALSformat scoring_matrix. Programs can read data files in this format as well as the regular format. (In the regular format, the sequences symbols are organized along the x axis (columns) and y axis (rows), where each symbol along the x axis is compared with each symbol along the y axis. The value of each pair of symbols compared is placed at the intersection of the appropriate row and column.)
Although it is not necessary, you can reformat a data file in columns back to its regular format using the command % reformat -COMParison scoring_matrix.
[ Program Manual | User's Guide | Data Files | Databases ]
Documentation Comments: doc-comments@gcg.com
Technical Support: help@gcg.com
Copyright (c) 1982, 1983, 1985, 1986, 1987, 1989, 1991, 1994, 1995, 1996, 1997, 1998 Genetics Computer Group Inc., a wholly owned subsidiary of Oxford Molecular Group, Inc. All rights reserved.
Licenses and Trademarks Wisconsin Package is a trademark of Genetics Computer Group, Inc. GCG and the GCG logo are registered trademarks of Genetics Computer Group, Inc.
All other product names mentioned in this documentation may be trademarks, and if so, are trademarks or registered trademarks of their respective holders and are used in this documentation for identification purposes only.